不同版本的JDK的HashMap的底层实现均有所不同
目录
JDK各个版本的源码查看
各个版本的源码查看:https://blog.csdn.net/zuochao_2013/article/details/79624579
android各个版本对应的JDK版本
https://blog.csdn.net/u010825468/article/details/78909550
通过改变build.gradle里的版本,即可查看对应JDK的源码。
后来我发现上面的这个表不准确,android我用SDK API 19,然后按照下面的方法,用010Editor来查看HashMap.class,发现竟然是JDK1.5。
https://blog.csdn.net/mengxiangxingdong/article/details/89437087
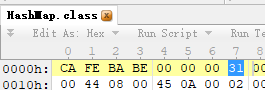
经我测试,真正的情况是API19、20都是JDK1.5,然后到了API21直接就JDK1.7了,没有用到JDK1.6。
大坑:
看了很多的博客,但是用android.jar里的源码一对比,怎么也对不上。
http://www.apkbus.com/thread-567645-1-1.html
原来android源码里的JDK和Java的JDK不是一个东西。
HashMap的特性
- 线程不安全
- 查询快
各个版本的HashMap的区别
https://www.nowcoder.com/discuss/151172
https://www.2cto.com/kf/201707/654203.html
https://blog.csdn.net/qq_36520235/article/details/82417949
JDK1.8的HashMap实现
https://www.cnblogs.com/little-fly/p/7344285.html
https://blog.csdn.net/qq_22200097/article/details/82791479
JDK1.7及以下的HashMap实现
- HashMap的主干是数组(不要以为带个Hash就和HashTable扯上关系了),数组的元素是HashMapEntry
- HashMapEntry是一个链表结构
https://blog.csdn.net/qq_38455201/article/details/80732839
https://blog.csdn.net/C18298182575/article/details/87167323
JDK1.5源码分析
主干数组初始化
/**
* Min capacity (other than zero) for a HashMap. Must be a power of two
* greater than 1 (and less than 1 << 30).
*/
private static final int MINIMUM_CAPACITY = 4;
/**
* An empty table shared by all zero-capacity maps (typically from default
* constructor). It is never written to, and replaced on first put. Its size
* is set to half the minimum, so that the first resize will create a
* minimum-sized table.
*/
private static final Entry[] EMPTY_TABLE
= new HashMapEntry[MINIMUM_CAPACITY >>> 1];
/**
* Constructs a new empty {@code HashMap} instance.
*/
@SuppressWarnings("unchecked")
public HashMap() {
table = (HashMapEntry<K, V>[]) EMPTY_TABLE;
threshold = -1; // Forces first put invocation to replace EMPTY_TABLE
}可见,HashMap的无参构造方法默认会创建一个大小为2的数组。
...版本太旧,就不往下分析了。
JDK1.6源码分析
https://blog.csdn.net/rocksteadypro/article/details/80082822
JDK1.7源码分析
https://www.cnblogs.com/xiaolovewei/p/7993521.html
https://www.cnblogs.com/xiaozhongfeixiang/archive/2019/09/23/11548563.html
需要注意的点:
-
key是如何计算出数组的下标的

哈希值求数组下标hash & (tab.length - 1);扩容为啥是2的倍数,和上面这个公式也是相关的:https://blog.csdn.net/ptsx0607/article/details/68945883,保证了散列的均匀性,哈希碰撞的机率就会减小。
-
头插法与链表
https://blog.csdn.net/insomsia/article/details/88367436
看put方法:@Override public V put(K key, V value) { if (key == null) { return putValueForNullKey(value); } int hash = secondaryHash(key); HashMapEntry重复元素判断:hash相同,key相同的肯定是同一个元素。
e.hash == hash && key.equals(e.key)但是可能不同的元素hash值不一样,算出的index却一样,但是又不是同一个元素(这就是哈希碰撞问题,哈希算法无法逃避这个问题),数组中的这个索引位置已经被占据了,那么我怎么存储这个新的元素呢?
请看HashMapEntry这个类:
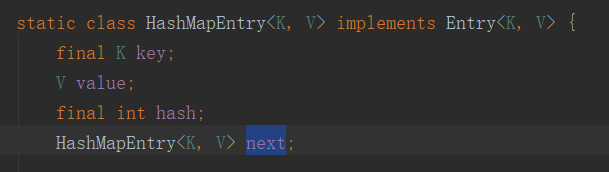
再看添加HashMapEntry的方法:void addNewEntry(K key, V value, int hash, int index) { table[index] = new HashMapEntry对于addNewEntry方法
如果index处本身没有元素占据,此时table[index]就是null。
那么直接就添加一个HashMapEntry元素,它的next指针指向原来Index位置的元素,也就是null;如果index处本身有元素,也就是哈希冲突了,
那么直接就添加一个HashMapEntry元素,它的next指针指向原来Index位置的元素,也就是哈希冲突的元素。头插法就是这么来的。key为null,HashMap是单独用一个HashMapEntry变量来存储的,并不是存储在数组中。所有的增删改查
都是先判断的key是否为null。对于计算机专业的人来说,得出上面的结论可能不难。但是对于非计算机专业的我来说,慢慢的发现了数据结构之类,简直太美妙了!
-
哈希冲突
https://www.iteye.com/blog/xiaolu123456-1485349
https://www.nowcoder.com/discuss/151172 -
并发导致的死循环问题
https://blog.csdn.net/pange1991/article/details/82377980
https://www.jianshu.com/p/61a829fa4e49
JDK1.8源码分析
知识点预备-红黑树
https://blog.csdn.net/u010890358/article/details/80496144 (详细解释每行代码)
0 条评论